Lessons learned scaling PostgreSQL database to 1.2bn records/month
Lessons learned scaling PostgreSQL database to 1.2bn records/month
Choosing where to host the database, materialising data and using database as a job queue
Go to the profile of Gajus Kuizinas
 Gajus Kuizinas
Jan 28 | 18 min read
Gajus Kuizinas
Jan 28 | 18 min read
This isn’t my first rodeo with large datasets. The authentication and product management database that I have designed for the largest UK public Wi-Fi provider had impressive volumes too. We were tracking authentication for millions of devices daily. However, that project had a funding that allowed us to pick any hardware, any supporting services and hire any DBAs to assist with replication/data warehousing/troubleshooting. Furthermore, all analytics queries/reporting were done off logical replicas and there were multiple sysadmins that looked after the supporting infrastructure. Whereas this was a venture of my own, with limited funding and 20x the volume.
Others’ mistakes
This is not to say that if we did have loadsamoney we would have spent it on purchasing top-of-the-line hardware, flashy monitoring systems or DBAs (Okay, maybe having a dedicated DBA would have been nice). Over many years of consulting I have developed a view that the root of all evil lies in the unnecessarily complex data processing pipeline. You don’t need a message queue for ETL and you don’t need an application-layer cache for database queries. More often than not, these are workarounds for the underlying database issues (e.g. latency, poor indexing strategy) that create more issues down the line. In ideal scenario, you want to have all data contained within a single database and all data loading operations abstracted into atomic transactions. My goal was not to repeat these mistakes.
Our goals
As you have already guessed, our PostgreSQL database became the central piece of the business (aptly called ‘mother’, although my co-founder insists that me calling various infrastructure components ‘mother’, ‘mothership’, ‘motherland’, etc is worrying). We don’t have a standalone message queue service, cache service or replicas for data warehousing. Instead of maintaining the supporting infrastructure, I have dedicated my efforts to eliminating any bottlenecks by minimizing latency, provisioning the most suitable hardware, and carefully planning the database schema. What we have is an easy to scale infrastructure with a single database and many data processing agents. I love the simplicity of it — if something breaks, we can pin point and fix the issue within minutes. However, a lot of mistakes were done along the way — this articles summarizes some of them.
Dataset
Before we dig in, let’s quickly summaries the dataset.
I am a co-founder of a company Applaudience. We aggregate cinema data. Our primary dataset includes movie showtimes, ticket prices and admissions. We combine this data with all sorts of supporting data, including data that we get from YouTube, Twitter and weather reports. The end result is a comprehensive time-series dataset describing the entire theatrical movie release window. The goal is to predict movie performance far into the future.
We currently track 3200+ cinemas across 22 territories in Europe and the US. This approximates to 47,000 showtimes/day. Every time a person reserves or purchases a ticket from either of these cinemas, we capture a snapshot describing attributes of every seat in the auditorium.
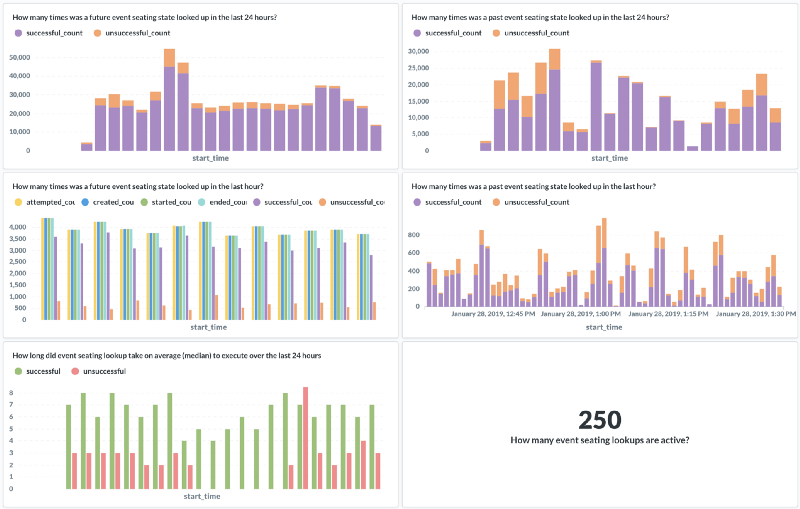 How we monitor data aggregation and detect anomalies is whole another topic. However, having PostgreSQL as the single source of truth about all data that is being aggregated and all the processes that aggregate the data made it a lot easier.
This adds up to 1.2bn records/month, and thats just for the admissions data.
How we monitor data aggregation and detect anomalies is whole another topic. However, having PostgreSQL as the single source of truth about all data that is being aggregated and all the processes that aggregate the data made it a lot easier.
This adds up to 1.2bn records/month, and thats just for the admissions data.
Choosing where to host the database
We went through several providers:
- Amazon
- Aiven.io
- Self-hosting
Google Cloud SQL for PosetgreSQL
We got USD 100k in startup credits from Google. This was the primary deciding factor for choosing their services. We used Cloud SQL for PostgreSQL for about 6 months. The primary reason we migrated away from Google SQL for PostgreSQL is because we discovered a bug that was causing data corruption. This was a known bug that is fixed in newer PostgreSQL versions. However, Google SQL for PostgreSQL is several versions behind. The lack of response from the support acknowledging the issue was a big enough red-flag to move on. I am glad we did move on, because it has been 8 months since we have raised the issue, and the version of PostgreSQL has not been updated:
postgres=> SELECT version();
PostgreSQL 9.6.6 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4, 64-bit(1 row)
Amazon RDS for PostgreSQL
Then we secured credits from Amazon and migrated to Amazon RDS for PostgreSQL — their version of PostgreSQL was kept up to date and my research into the RDS community raised no concerns. However, Amazon RDS for PostgreSQL does not support TimescaleDB extension that we planed to use for partitioning of our database. As Amazon announced Timestream (their own time-series database), it became clear that this requirement will not be addressed in the foreseeable future (this issue has been already open for 2 years).
Aiven.io
Then we moved to Aiven.io. Aiven.io manages PostgreSQL database for you on your cloud service provider of choice. It had all the extensions that I needed (including TimescaleDB), it did not lock us in with a particular server provider (meaning we could host our Kubernetes cluster on either of the Aiven.io supported providers), their support was helpful from the first interaction and my due diligence came back only with praise. However, what I have overlooked is that you do not get superuser access. This resulted in numerous issues (e.g., various maintenance procedures we have been using stopped working and we couldn’t use our monitoring software due to permission issues; unable to use auto_explain; logical replication requires custom extensions) and long outages that could have been prevented.
In general, I didn’t understand what added value Aiven.io provides – we weren’t even warned when the database was running out of storage.
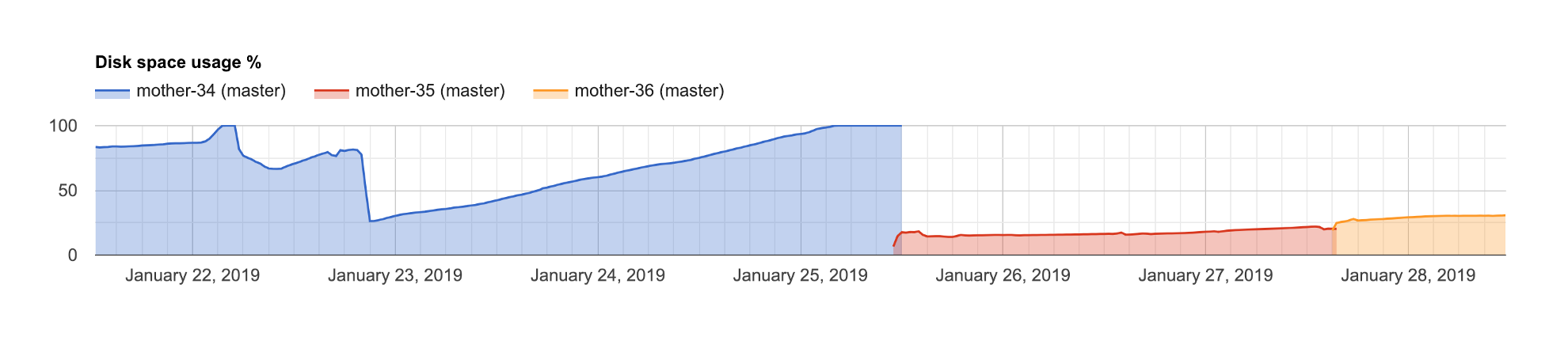
When this happened, support offered to upgrade the instance to one with a larger volume. While this is a fine solution, it caused a longer than necessary outage. Someone with SSH access could have diagnosed and fixed this issue in couple of minutes.
And when we started to experience continuous outages due to (what later turned out to be) a bug in TimescaleDB extension used by Aiven.io support did not offer any workarounds for the issue.
We’re looking into this issue and working with the timescale team, but response to most things isn’t immediate. Our help article at https://help.aiven.io/support/aiven-support-details describes the response times we provide.
Which is a terribly passive response when your customer’s server is in a crashing loop (Two days later: No follow up from Aiven.io.)
Despite me giving shit to Aiven.io over a couple of issues, overall their support was great. Tolerating my questions that are already covered in documentation and aiding with troubleshooting issues. The primary reason we are moving away is the lack of SSH/superuser.
Self-hosted
All this time I was trying to avoid the unavoidable — managing the database ourselves. Now we are renting our own hardware and maintain the database. We have a lot better hardware than any of the cloud service providers could offer, point in time recovery (thanks to Barman) and no vendor lock-in, and (on paper) it is about 30% cheaper than hosting using Google Cloud or AWS. That 30% we can use to hire a freelance DBA to check in on the servers once a day.
Takeaway
The takeaway here is that Google and Amazon prioritise their proprietary solutions (Google BigQuery, AWS Redshift). Therefore, you must plan for what features you will require in the future. For a simple database that will not grow into billions of records and does not require custom extensions, I would pick either without a second thought (the near instant ability to scale the instance, migrate servers to different territories, point-in-time recovery, built-in monitoring tools and managed replication saves a lot of time.).
If your business is all about the data and you know that you will require custom hardware configuration and whatnot, then your best bet is hosting and managing the database yourself. That said, logical migration is simple enough — if you can start with either of the managed providers and leverage their startup credits, then that is a great way to kick start a project and you can migrate later as/if it becomes necessary.
If I would start over and would have spent time to estimate how quick and how large we are going to grow, I would have used bare-metal setup and hired a freelance DBA from the first day.
Bonus: Performance
My primary criteria for choosing managed services was the reduced management overhead. I assumed that the cost and hardware is going to be about the same. Aiven.io has written an article where they compare PostgreSQL performance in AWS, GCP, Azure, DO and UpCloud (GCP beats AWS by a factor of 2 in all tests).
Materializing data
Did I mention that this is the first time I have used PostgreSQL?
Up to this venture, I have been primarily using MySQL. The reason I decided to use PostgreSQL for this startup was because PostgreSQL has support for materialized views and programming languages. I thought that the materialized views is a good enough feature on its own to learn PostgreSQL. In contrast, I thought I will never run scripts in the database (MySQL teaches you that database is only for storing data and all logic must be implemented in the application code).
Two years later, we got rid of most materialized views and we are using hundreds of custom procedures. But before that, there were multiple botched attempts at using materialized views.
First attempt at using PostgreSQL materialized views
My first use case for materialized views could be summarized as ‘having a base table enriched with a metadata’, e.g.
CREATE MATERIALIZED VIEW venue_view AS
WITH
auditorium_with_future_events AS (
SELECT
e1.venue_id,
e1.auditorium_id
FROM event e1
WHERE
-- The 30 days interval ensures that we do not remove auditoriums
-- that are temporarily unavailable.
e1.start_time > now() - INTERVAL '30 day' AND
e1.auditorium_id IS NOT NULL
GROUP BY
e1.venue_id,
e1.auditorium_id
),
auditorium_with_future_events_count AS (
SELECT
awfe1.venue_id,
count(*) auditorium_count
FROM auditorium_with_future_events awfe1
GROUP BY
awfe1.venue_id
),
venue_auditorium_seat_count AS (
SELECT DISTINCT ON (e1.venue_id, e1.auditorium_id)
e1.venue_id,
e1.auditorium_id,
e1.seat_count
FROM auditorium_with_future_events awfe1
INNER JOIN event e1 ON e1.venue_id = awfe1.venue_id AND e1.auditorium_id = awfe1.auditorium_id
WHERE
e1.start_time > now() - INTERVAL '30 day' AND
e1.auditorium_id IS NOT NULL AND
e1.seat_count IS NOT NULL
ORDER BY
e1.venue_id,
e1.auditorium_id
),
venue_seat_count AS (
SELECT
vasc1.venue_id,
sum(vasc1.seat_count) seat_count
FROM venue_auditorium_seat_count vasc1
GROUP BY vasc1.venue_id
)
SELECT DISTINCT ON (v1.id)
v1.id,
v1.google_place_id,
v1.fuid,
v1.cinema_id,
v1.street_1,
v1.street_2,
v1.postcode,
v1.coordinates,
gp1.country_id,
gp1.timezone_id,
COALESCE(v1.phone_number, c1.phone_number) AS phone_number,
v1.display_name AS name,
COALESCE(v1.alternative_url, v1.url) AS url,
v1.permanently_closed_at,
awfec1.auditorium_count,
nearest_venue.id nearest_venue_id,
CASE
WHEN nearest_venue.id IS NULL
THEN NULL
ELSE round(ST_DistanceSphere(gp1.location, nearest_venue.location))
END nearest_venue_distance,
vsc1.seat_count seat_count
FROM venue v1
LEFT JOIN venue_seat_count vsc1 ON vsc1.venue_id = v1.id
LEFT JOIN google_place gp1 ON gp1.id = v1.google_place_id
LEFT JOIN LATERAL (
SELECT
v2.id,
gp2.location
FROM venue v2
INNER JOIN google_place gp2 ON gp2.id = v2.google_place_id
WHERE v2.id != v1.id
ORDER BY gp1.location <-> gp2.location
LIMIT 1
) nearest_venue ON TRUE
LEFT JOIN auditorium_with_future_events_count awfec1 ON awfec1.venue_id = v1.id
INNER JOIN cinema c1 ON c1.id = v1.cinema_id
WITH NO DATA;
CREATE UNIQUE INDEX ON venue_view (id);
CREATE INDEX ON venue_view (google_place_id);
CREATE INDEX ON venue_view (cinema_id);
CREATE INDEX ON venue_view (country_id);
CREATE INDEX ON venue_view (nearest_venue_id);
Here venue is the base table that we extend with additional data and call it venue_view. There were only two rules to adhere:
_view must include all columns of the base table. _view must include all rows of the base table.
There is nothing wrong with the above query. This approach worked for a long time. However, as the number of records grew to millions and billions the time it took to refresh materialized views grew from a couple of seconds to hours. (If you are not familiar with materialized views, then it is worth noting that you can only refresh the entire materialized view; there is no way to refresh a subset of a view based on a condition.)
Second attempt: divide and conquer
I tried to solve the issue by breaking down MVs into multiple smaller MVs, e.g.
(Notice that we have moved queries from CTEs to dedicated MVs.)
CREATE MATERIALIZED VIEW auditorium_with_future_events_view
SELECT
e1.venue_id,
e1.auditorium_id
FROM event e1
WHERE
-- The 30 days interval ensures that we do not remove auditoriums
-- that are temporarily unavailable.
e1.start_time > now() - INTERVAL '30 day' AND
e1.auditorium_id IS NOT NULL
GROUP BY
e1.venue_id,
e1.auditorium_id
WITH NO DATA;
CREATE UNIQUE INDEX ON auditorium_with_future_events_view (venue_id, auditorium_id);
CREATE MATERIALIZED VIEW venue_auditorium_seat_count_view
SELECT DISTINCT ON (e1.venue_id, e1.auditorium_id)
e1.venue_id,
e1.auditorium_id,
e1.seat_count
FROM auditorium_with_future_events_view awfe1
INNER JOIN event e1 ON e1.venue_id = awfe1.venue_id AND e1.auditorium_id = awfe1.auditorium_id
WHERE
e1.start_time > now() - INTERVAL '30 day' AND
e1.auditorium_id IS NOT NULL AND
e1.seat_count IS NOT NULL
ORDER BY
e1.venue_id,
e1.auditorium_id
WITH NO DATA;
CREATE UNIQUE INDEX ON venue_auditorium_seat_count_view (venue_id, auditorium_id);
CREATE MATERIALIZED VIEW venue_view AS
WITH
auditorium_with_future_events_count AS (
SELECT
awfe1.venue_id,
count(*) auditorium_count
FROM auditorium_with_future_events_view awfe1
GROUP BY
awfe1.venue_id
),
venue_seat_count AS (
SELECT
vasc1.venue_id,
sum(vasc1.seat_count) seat_count
FROM venue_auditorium_seat_count_view vasc1
GROUP BY vasc1.venue_id
)
SELECT DISTINCT ON (v1.id)
v1.id,
v1.google_place_id,
v1.fuid,
v1.cinema_id,
v1.street_1,
v1.street_2,
v1.postcode,
v1.coordinates,
gp1.country_id,
gp1.timezone_id,
COALESCE(v1.phone_number, c1.phone_number) AS phone_number,
v1.display_name AS name,
COALESCE(v1.alternative_url, v1.url) AS url,
v1.permanently_closed_at,
awfec1.auditorium_count,
nearest_venue.id nearest_venue_id,
CASE
WHEN nearest_venue.id IS NULL
THEN NULL
ELSE round(ST_DistanceSphere(gp1.location, nearest_venue.location))
END nearest_venue_distance,
vsc1.seat_count seat_count
FROM venue v1
LEFT JOIN venue_seat_count vsc1 ON vsc1.venue_id = v1.id
LEFT JOIN google_place gp1 ON gp1.id = v1.google_place_id
LEFT JOIN LATERAL (
SELECT
v2.id,
gp2.location
FROM venue v2
INNER JOIN google_place gp2 ON gp2.id = v2.google_place_id
WHERE v2.id != v1.id
ORDER BY gp1.location <-> gp2.location
LIMIT 1
) nearest_venue ON TRUE
LEFT JOIN auditorium_with_future_events_count awfec1 ON awfec1.venue_id = v1.id
INNER JOIN cinema c1 ON c1.id = v1.cinema_id
WITH NO DATA;
CREATE UNIQUE INDEX ON venue_view (id);
CREATE INDEX ON venue_view (google_place_id);
CREATE INDEX ON venue_view (cinema_id);
CREATE INDEX ON venue_view (country_id);
CREATE INDEX ON venue_view (nearest_venue_id);
The benefit of this approach is that:
- We broke-down one long-transaction into many shorter transactions.
- We are able to use indexes to speed up the JOINs.
- We are able to refresh individual materialized views (some data changes more often than the other).
The downside of this approach is that it proliferated the number of materialized views that we use and required to develop a custom solution to orchestrate refreshing of the materialized views. At the time, it seemed reasonable and I went with it. Thus was materialized_view_refresh_schedule table born and our first in-database queue:
```CREATE TABLE materialized_view_refresh_schedule ( id SERIAL PRIMARY KEY, materialized_view_name citext NOT NULL, refresh_interval interval NOT NULL, last_attempted_at timestamp with time zone, maximum_execution_duration interval NOT NULL DEFAULT ‘00:30:00’::interval ); CREATE UNIQUE INDEX materialized_view_refresh_schedule_materialized_view_name_idx ON materialized_view_refresh_schedule(materialized_view_name citext_ops); CREATE TABLE materialized_view_refresh_schedule_execution ( id integer DEFAULT nextval(‘materialized_view_refresh_id_seq’::regclass) PRIMARY KEY, materialized_view_refresh_schedule_id integer NOT NULL REFERENCES materialized_view_refresh_schedule(id) ON DELETE CASCADE, started_at timestamp with time zone NOT NULL, ended_at timestamp with time zone, execution_is_successful boolean, error_name text, error_message text, terminated_at timestamp with time zone, CONSTRAINT materialized_view_refresh_schedule_execution_check CHECK (terminated_at IS NULL OR ended_at IS NOT NULL) ); CREATE INDEX materialized_view_refresh_schedule_execution_materialized_view_ ON materialized_view_refresh_schedule_execution(materialized_view_refresh_schedule_id int4_ops);
Names of the materialized views are stored in *aterialized_view_refresh_schedule*table with instructions as to how often they need be refreshed. A separate program was written to perform materialization using these instructions.
CREATE OR REPLACE FUNCTION schedule_new_materialized_view_refresh_schedule_execution() RETURNS table(materialized_view_refresh_schedule_id int) AS \(BEGIN RETURN QUERY UPDATE materialized_view_refresh_schedule SET last_attempted_at = now() WHERE id IN ( SELECT mvrs1.id FROM materialized_view_refresh_schedule mvrs1 LEFT JOIN LATERAL ( SELECT 1 FROM materialized_view_refresh_schedule_execution mvrse1 WHERE mvrse1.ended_at IS NULL AND mvrse1.materialized_view_refresh_schedule_id = mvrs1.id ) AS unendeded_materialized_view_refresh_schedule_execution ON TRUE WHERE unendeded_materialized_view_refresh_schedule_execution IS NULL AND ( mvrs1.last_attempted_at IS NULL OR mvrs1.last_attempted_at + mvrs1.refresh_interval < now() ) ORDER BY mvrs1.last_attempted_at ASC NULLS FIRST LIMIT 1 FOR UPDATE OF mvrs1 SKIP LOCKED ) RETURNING id; END\) LANGUAGE plpgsql;
This program would call *chedule_new_materialized_view_refresh_schedule_execution* to schedule a materialized view refresh, evaluate *REFRESH MATERIALIZED VIEW … CONCURRENTLY*, and log the result. In general, this approach worked well. However, we soon outgrew this approach. A view that requires to scan an entire table was not feasible for large tables with billions of records.
## Third attempt: using MVs to abstract a subset of data
I have described how we have used MVs to effectively extend a table. This approach did not scale with large tables. Thus the third iteration was born: instead of using materialized views to extend the base table, create materialized views that abstract a data domain. Due to its size venue_view could remain as it was, but a hypothetical view such as event_view with billions of records would become last_week_event, future_event, etc. This approach works and we continue to use several such materialized views.
## Fourth attempt: materialized table columns
While the latter approach covered all our day to day operations, we still needed to run queries on the historical data. Running these queries without materialized views would take a lot of index planning for individual queries. Furthermore, running long transactions against the master instance would have prevented autovacuum and caused table bloat. I could have created a logical replication and allowed analysts to run whatever queries on that instance without blocking autovacuum. However, the bigger problem is that as a startup we cannot afford queries that take hours or days to run. We need to move faster than anyone else. Thus was born the current solution: materialized table columns.
The principal is simple:
Tables that describe entities that we want to enrich with additional information are altered to include a materialized_at timestamptz column and a column for each data point that we want to materialize. In the example of the venue_view, we would get rid of the materialized view entirely and add materialized_at, country_id, timezone_id, phone_number and other columns that were present in the original venue_view materialized view to the venue table itself.
Then there is a script that observes all tables that have materialized_at column and every time it detects a row where materialized_at IS NULL it computes new values for the materialized columns and updates the row, e.g.
CREATE OR REPLACE FUNCTION materialize_event_seat_state_change() RETURNS void AS \(BEGIN WITH event_seat_state_count AS ( SELECT essc1.id, count(*)::smallint seat_count, count(*) FILTER (WHERE ss1.nid = 'BLOCKED')::smallint seat_blocked_count, count(*) FILTER (WHERE ss1.nid = 'BROKEN')::smallint seat_broken_count, count(*) FILTER (WHERE ss1.nid = 'EMPTY')::smallint seat_empty_count, count(*) FILTER (WHERE ss1.nid = 'HOUSE')::smallint seat_house_count, count(*) FILTER (WHERE ss1.nid = 'SOLD')::smallint seat_sold_count, count(*) FILTER (WHERE ss1.nid = 'UNKNOWN')::smallint seat_unknown_count, count(*) FILTER (WHERE ss1.id IS NULL)::smallint seat_unmapped_count, count(*) FILTER (WHERE ss1.nid IN ('BLOCKED', 'BROKEN', 'HOUSE', 'SOLD', 'UNKNOWN')) seat_unavailable_count FROM event e1 LEFT JOIN event_seat_state_change essc1 ON essc1.event_id = e1.id LEFT JOIN event_seat_state_change_seat_state esscss1 ON esscss1.event_seat_state_change_id = essc1.id LEFT JOIN cinema_foreign_seat_state fcss1 ON fcss1.id = cinema_foreign_seat_state_id LEFT JOIN seat_state ss1 ON ss1.id = fcss1.seat_state_id WHERE essc1.id IN ( SELECT id FROM event_seat_state_change WHERE materialized_at IS NULL ORDER BY materialized_at DESC LIMIT 100 ) GROUP BY essc1.id ) UPDATE event_seat_state_change essc1 SET materialized_at = now(), seat_count = essc2.seat_count, seat_blocked_count = essc2.seat_blocked_count, seat_broken_count = essc2.seat_broken_count, seat_empty_count = essc2.seat_empty_count, seat_house_count = essc2.seat_house_count, seat_sold_count = essc2.seat_sold_count, seat_unknown_count = essc2.seat_unknown_count, seat_unmapped_count = essc2.seat_unmapped_count FROM event_seat_state_count essc2 WHERE essc1.id = essc2.id; END\) LANGUAGE plpgsql SET work_mem=’1GB’ SET max_parallel_workers_per_gather=4;
Once again, this required to write a custom solution that observes tables and manages their materialization, row and column expiration logic, etc. I am currently developing an open-source version that I plan to publish in the near future.
The biggest benefit of this approach is that you can be as granular as you want about updating the materialized table columns: you can update individual rows and you can update individual columns (e.g. when new materialized column is added and there is a need to populate new column values, you would only need to generate value for that column; no need to run full materialization query). Furthermore, as the updates are granular, they can all be applied in a near real-time.
## Takeaway
The takeaway here is that PostgreSQL materialized views are a great feature for small datasets. However, as the dataset grows, careful planning is required for how data is going to be accessed and what materialization strategy supports such requirement. Using a combination of granular materialized views and materialized table columns we were able to enrich the database in real-time and use it for all our analytics queries without adding the complexity of a logical replicate for data-warehousing.
## Using database as a job queue
This has less to do with the volume of the data that we process and more with how we are using the database. As I mentioned earlier, my goal was to reduce the number of services that participate in the data processing pipeline. The added benefit of containing the job queue within a database is that you are able to keep and query records of all jobs (and their attributes) associated with every data point that is in the database. Being able query jobs and logs associated with every data point, join it with parent and descendent jobs, etc. proved extremely valuable for flagging failing jobs and pin-pointing the origin of the issue.

#### Building a simple, reliable and efficient concurrent work queues using PostgreSQL.
It is worth noting that normally, a RDBMs would be a poor choice for a concurrent job queue (for reasons outlined in [What is SKIP LOCKED for in PostgreSQL 9.5?](https://blog.2ndquadrant.com/what-is-select-skip-locked-for-in-postgresql-9-5/)). However, in case of PostgreSQL, we can use *FOR UPDATE … SKIP LOCKED* to build a simple, reliable and efficient concurrent work queues. The downside is the performance:
> Each transaction scans the table and skips over locked rows, so with high numbers of active workers it can land up doing a bit of work to acquire a new item. It’s not just popping items off a stack. The query will probably have to walk an index with an index scan, fetching each candidate item from the heap and checking the lock status. With any reasonable queue this will all be in memory but it’s still a fair bit of churn.
– https://blog.2ndquadrant.com/what-is-select-skip-locked-for-in-postgresql-9-5/
I did not pay enough attention to this warning and landed myself in quite a bit of trouble.
The short version is that the first version of the query used to schedule jobs took a long time to execute, which meant meant that worker nodes were primarily sitting idle, we were wasting valuable resources and important tasks were not done in time.
The solution was quite simple: a dedicated table that is populated with a list of outstanding tasks. Picking up a job from this table is as simple as:
CREATE OR REPLACE FUNCTION schedule_cinema_data_task() RETURNS table(cinema_data_task_id int) AS \(DECLARE scheduled_cinema_data_task_id int; BEGIN UPDATE cinema_data_task_queue SET attempted_at = now() WHERE id = ( SELECT cdtq1.id FROM cinema_data_task_queue cdtq1 WHERE cdtq1.attempted_at IS NULL ORDER BY cdtq1.id ASC LIMIT 1 FOR UPDATE OF cdtq1 SKIP LOCKED ) RETURNING cinema_data_task_queue.cinema_data_task_id INTO scheduled_cinema_data_task_id; UPDATE cinema_data_task SET last_attempted_at = now() WHERE id = scheduled_cinema_data_task_id; RETURN QUERY SELECT scheduled_cinema_data_task_id; END\) LANGUAGE plpgsql SET work_mem=’100MB’;
The main task definition is stored in *cinema_data_task . cinema_data_task_queue* is used only for queuing ready to execute tasks.
The biggest gotcha is that the priority and limitations of which tasks can run changes every time a new task is executed. Therefore, instead of scheduling large number of jobs, we are running a process that every second checks if the queue is running dry and populates it with new tasks, e.g.
CREATE OR REPLACE FUNCTION update_cinema_data_task_queue() RETURNS void AS \(DECLARE outstanding_task_count int; BEGIN SELECT count(*) FROM cinema_data_task_queue WHERE attempted_at IS NULL INTO outstanding_task_count; IF outstanding_task_count < 100 THEN INSERT INTO cinema_data_task_queue (cinema_data_task_id) SELECT cdtq1.cinema_data_task_id FROM cinema_data_task_queue(100, 50, 100, false) cdtq1 WHERE NOT EXISTS ( SELECT 1 FROM cinema_data_task_queue WHERE cinema_data_task_id = cdtq1.cinema_data_task_id AND attempted_at IS NULL ) ON CONFLICT (cinema_data_task_id) WHERE attempted_at IS NULL DO NOTHING; END IF; END\) LANGUAGE plpgsql SET work_mem=’50MB’; ```
After the task is completed, the reference to the task is deleted from cinema_data_task_queue . This ensured that table scans are quick and do not keep the CPU busy.
This approach allowed us to scale to 2000+ concurrent data aggregation agents.
Note: The 100 outstanding tasks limit is somewhat arbitrary. I have experimented with values as large as 10k without any measurable performance penalty. However, as long as we can keep the queue from drying out, then the more granular the scheduling is, the better we load-balance data aggregation between different sources, the sooner we can stop pulling data from failing data sources, etc.
Takeway
If you are going to use database as a job queue, the table containing the jobs must be reasonable size and the query used to schedule the next job execution must not take more than couple of milliseconds.
Miscs
These 3 things were the biggest challenges when scaling the database. Some other gotchas include:
- When you have hundreds of clients each running dozens of queries a second then latency between the database and the database clients matters a lot. I have observed that the latency between our database (at the time) hosted on AWS RDS and our Kubernetes cluster hosted on GKE was 12ms. By moving the database to the same datacenter and reducing latency to <1ms, our job throughout increased 4x.
 Identifying latency between different cloud providers.
Identifying latency between different cloud providers.
- Column order matters. We have tables with 60+ columns. Ordering columns to avoid padding saved 20%+ storage (https://blog.2ndquadrant.com/on-rocks-and-sand/).
- If you are going to run long-queries on master, evaluate vacuum_freeze_table_age to prevent table bloat.
- Two configurations that I do not see being talked enough about: from_collapse_limit, join_collapse_limit . Both configurations default to 8. Not knowing about these configuration caused a lot of headache debugging confusing execution plans. We increased from_collapse_limit to 20 and join_collapse_limit to 50. It is unclear to me what is the reason the defaults are low. There appears to be no penalty for having them infinitely high.
- Plan for table bloat and how to repair it. As the database grows large, VACUUM FULL becomes unfeasible. Explore pg_repack and pg_squeeze .
- Constantly monitor pg_stat_statements . Sort by total_time. Top queries are the low hanging fruits.
- Constantly monitor pg_stat_user_tables. Identify underused indexes and monitor dead tuple accumulation.
- Constantly monitor pg_stat_activity . Identify bottlenecks due to locks and refactor the offending transactions.
Bonus: Slonik PostgreSQL client
We were using PostgreSQL a lot. We began by using node-postgres. node-postgres provided a great protocol abstraction. However, the code felt verbose and we kept adding new helpers to abstract repeating patterns and to enable debugging experience. We needed these helpers across many different programs. Therefore, I ended up developing Slonik – A PostgreSQL client with strict types, detail logging and assertions.
Slonik helps us to keep the code lean, protects against SQL injections, enables detail logging and application log correlation with auto_explain.
Acknowledgements
I want to thank Freenode #postgresql community for the warm welcome, mentoring and aiding throughout my PostgreSQL journey. Whether I asked esoteric questions, dumb questions, needed help debugging an issue or just wanted to learn a bit of history about PostgreSQL origins, I always got full support from #postgresql community. I especially want to thank Berge, depesz, ilmari, Myon, nickb, peerce, RhodiumToad, Snow-Man, xocolatl and Zr40: your support halved the time I needed to learn as much as I have up to now.
Programming Postgres Postgresql Database Database Administration
Gajus Kuizinas
Gajus Kuizinas
Medium member since Jan 2019
Software architect, startup adviser. Editor of https://medium.com/applaudience. Founder of https://go2cinema.com.